Optimizing spiking neural networks¶
Almost all deep learning methods are based on gradient descent, which means that the network being optimized needs to be differentiable. Deep neural networks are usually built using rectified linear or sigmoid neurons, as these are differentiable nonlinearities. However, in biological neural modelling we often want to use spiking neurons, which are not differentiable. So the challenge is how to apply deep learning methods to spiking neural networks.
A method for accomplishing this is presented in Hunsberger and Eliasmith (2016). The basic idea is to use a differentiable approximation of the spiking neurons during the training process, and the actual spiking neurons during inference. NengoDL will perform these transformations automatically if the user tries to optimize a model containing a spiking neuron model that has an equivalent, differentiable rate-based implementation. In this example we will use these techniques to develop a network to classify handwritten digits (MNIST) in a spiking convolutional network.
In [1]:
%matplotlib inline
import gzip
import pickle
from urllib.request import urlretrieve
import zipfile
import nengo
import nengo_dl
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
First we’ll load the training data, the MNIST digits/labels.
In [2]:
urlretrieve("http://deeplearning.net/data/mnist/mnist.pkl.gz", "mnist.pkl.gz")
with gzip.open("mnist.pkl.gz") as f:
train_data, _, test_data = pickle.load(f, encoding="latin1")
train_data = list(train_data)
test_data = list(test_data)
for data in (train_data, test_data):
one_hot = np.zeros((data[0].shape[0], 10))
one_hot[np.arange(data[0].shape[0]), data[1]] = 1
data[1] = one_hot
for i in range(3):
plt.figure()
plt.imshow(np.reshape(train_data[0][i], (28, 28)))
plt.axis('off')
plt.title(str(np.argmax(train_data[1][i])));


We will use
TensorNodes to
construct the network, as they allow us to easily include features such
as convolutional connections. To make things even easier, we’ll use
nengo_dl.tensor_layer. This is a utility function for constructing
TensorNodes that mimics the layer-based syntax of many deep learning
packages (e.g.
tf.layers).
The full documentation for this function can be found
here.
tensor_layer is used to build a sequence of layers, where each layer
takes the output of the previous layer and applies some transformation
to it. So when we build a tensor_layer we pass it the input to the
layer, the transformation we want to apply (expressed as a function that
accepts a tf.Tensor as input and produces a tf.Tensor as
output), and any arguments to that transformation function.
tensor_layer also has optional transform and synapse
parameters that set those respective values on the Connection from the
previous layer to the one being constructed.
Normally all signals in a Nengo model are (batched) vectors. However,
certain layer functions, such as convolutional layers, may expect a
different shape for their inputs. If the shape_in argument is
specified for a tensor_layer then the inputs to the layer will
automatically be reshaped to the given shape. Note that this shape does
not include the batch dimension on the first axis, as that will be
automatically set by the simulation.
tensor_layer can also be passed a Nengo NeuronType, instead of a
Tensor function. In this case tensor_layer will construct an
Ensemble implementing the given neuron nonlinearity (the rest of the
arguments work the same).
Note that tensor_layer is just a syntactic wrapper for constructing
TensorNodes or Ensembles; anything we build with a
tensor_layer we could instead construct directly using those
underlying components. tensor_layer just simplifies the construction
of this common layer-based pattern.
In [3]:
with nengo.Network() as net:
# set some default parameters for the neurons that will make
# the training progress more smoothly
net.config[nengo.Ensemble].max_rates = nengo.dists.Choice([100])
net.config[nengo.Ensemble].intercepts = nengo.dists.Choice([0])
neuron_type = nengo.LIF(amplitude=0.01)
# we'll make all the nengo objects in the network
# non-trainable. we could train them if we wanted, but they don't
# add any representational power. note that this doesn't affect
# the internal components of tensornodes, which will always be
# trainable or non-trainable depending on the code written in
# the tensornode.
nengo_dl.configure_settings(trainable=False)
# the input node that will be used to feed in input images
inp = nengo.Node([0] * 28 * 28)
# add the first convolutional layer
x = nengo_dl.tensor_layer(
inp, tf.layers.conv2d, shape_in=(28, 28, 1), filters=32,
kernel_size=3)
# apply the neural nonlinearity
x = nengo_dl.tensor_layer(x, neuron_type)
# add another convolutional layer
x = nengo_dl.tensor_layer(
x, tf.layers.conv2d, shape_in=(26, 26, 32),
filters=64, kernel_size=3)
x = nengo_dl.tensor_layer(x, neuron_type)
# add a pooling layer
x = nengo_dl.tensor_layer(
x, tf.layers.average_pooling2d, shape_in=(24, 24, 64),
pool_size=2, strides=2)
# another convolutional layer
x = nengo_dl.tensor_layer(
x, tf.layers.conv2d, shape_in=(12, 12, 64),
filters=128, kernel_size=3)
x = nengo_dl.tensor_layer(x, neuron_type)
# another pooling layer
x = nengo_dl.tensor_layer(
x, tf.layers.average_pooling2d, shape_in=(10, 10, 128),
pool_size=2, strides=2)
# linear readout
x = nengo_dl.tensor_layer(x, tf.layers.dense, units=10)
# we'll create two different output probes, one with a filter
# (for when we're simulating the network over time and
# accumulating spikes), and one without (for when we're
# training the network using a rate-based approximation)
out_p = nengo.Probe(x)
out_p_filt = nengo.Probe(x, synapse=0.1)
Next we can construct a Simulator for that network.
In [4]:
minibatch_size = 200
sim = nengo_dl.Simulator(net, minibatch_size=minibatch_size)
Build finished in 0:00:00
|# Optimizing graph: creating signals | 0:00:00
/home/travis/build/nengo/nengo-dl/nengo_dl/simulator.py:127: UserWarning: No GPU support detected. It is recommended that you install tensorflow-gpu (`pip install tensorflow-gpu`).
"No GPU support detected. It is recommended that you "
Optimization finished in 0:00:01
Construction finished in 0:00:02
Now we need to train this network to classify MNIST digits. First we load our input images and target labels.
In [5]:
# note that we need to add the time dimension (axis 1), which will be a
# single step during training
train_inputs = {inp: train_data[0][:, None, :]}
train_targets = {out_p: train_data[1][:, None, :]}
# when testing our network with spiking neurons we will need to run it over time,
# so we repeat the input/target data for a number of timesteps. we're also going
# to reduce the number of test images, just to speed up this example.
n_steps = 30
test_inputs = {inp: np.tile(test_data[0][:minibatch_size*2, None, :],
(1, n_steps, 1))}
test_targets = {out_p_filt: np.tile(test_data[1][:minibatch_size*2, None, :],
(1, n_steps, 1))}
Next we need to define our objective (error) function. Because this is a classification task we’ll use cross entropy, instead of the default mean squared error.
In [6]:
def objective(x, y):
return tf.nn.softmax_cross_entropy_with_logits_v2(logits=x, labels=y)
The last thing we need to specify is the optimizer. For this example we’ll use RMSProp.
In [7]:
opt = tf.train.RMSPropOptimizer(learning_rate=0.001)
In order to quantify the network’s performance we will also define a classification error function (the percentage of test images classified incorrectly). We could use the cross entropy objective, but classification error is easier to interpret. Note that we use the output from the network on the final timestep (as we are simulating the network over time).
In [8]:
def classification_error(outputs, targets):
return 100 * tf.reduce_mean(
tf.cast(tf.not_equal(tf.argmax(outputs[:, -1], axis=-1),
tf.argmax(targets[:, -1], axis=-1)),
tf.float32))
print("error before training: %.2f%%" % sim.loss(
test_inputs, test_targets, {out_p_filt: classification_error}))
error before training: 91.25%
Now we are ready to train the network. In order to keep this example
relatively quick we are going to download some pretrained weights.
However, if you’d like to run the training yourself set
do_training=True below.
In [9]:
do_training = False
if do_training:
# run training
sim.train(train_inputs, train_targets, opt, objective={out_p: objective},
n_epochs=10)
# save the parameters to file
sim.save_params("./mnist_params")
else:
# download pretrained weights
urlretrieve(
"https://drive.google.com/uc?export=download&id=18ErAZh0LFRaISLHDM-dJjjnzqvYfyjo0",
"mnist_params.zip")
with zipfile.ZipFile("mnist_params.zip") as f:
f.extractall()
# load parameters
sim.load_params("./mnist_params")
Now we can check the classification error again, with the trained parameters.
In [10]:
print("error after training: %.2f%%" % sim.loss(
test_inputs, test_targets, {out_p_filt: classification_error}))
error after training: 0.75%
We can see that the spiking neural network is achieving ~1% error, which
is what we would expect for MNIST. n_steps could be increased to
further improve performance, since we would get a more accurate measure
of each spiking neuron’s output.
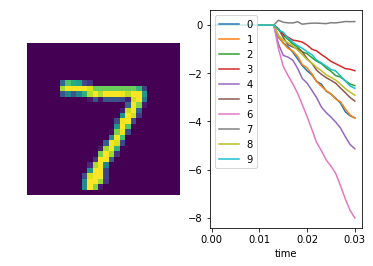
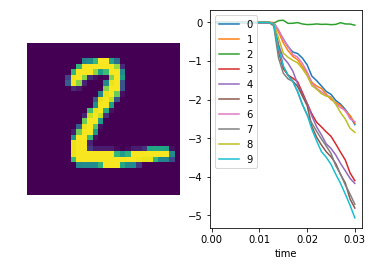
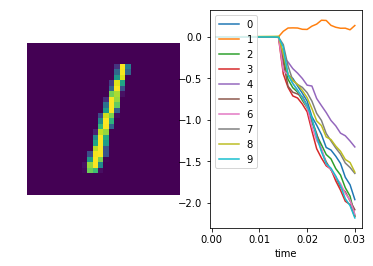
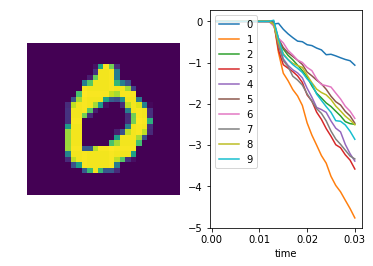
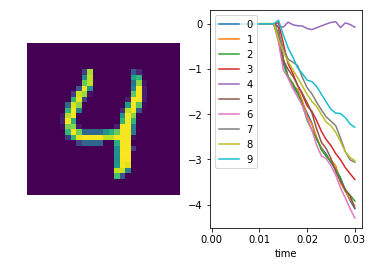
We can also plot some example outputs from the network, to see how it is performing over time.
In [11]:
sim.run_steps(n_steps, input_feeds={inp: test_inputs[inp][:minibatch_size]})
for i in range(5):
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(np.reshape(test_data[0][i], (28, 28)))
plt.axis('off')
plt.subplot(1, 2, 2)
plt.plot(sim.trange(), sim.data[out_p_filt][i])
plt.legend([str(i) for i in range(10)], loc="upper left")
plt.xlabel("time")
Simulation finished in 0:00:51
In [12]:
sim.close()