
- Introduction
- Installation
- User guide
- API reference
- Examples
- Coming from Nengo to NengoDL
- Coming from TensorFlow to NengoDL
- Integrating a Keras model into a Nengo network
- Optimizing a spiking neural network
- Converting a Keras model to a spiking neural network
- Legendre Memory Units in NengoDL
- Optimizing a cognitive model
- Optimizing a cognitive model with temporal dynamics
- Additional resources
- Project information
Legendre Memory Units in NengoDL¶
![]()
Legendre Memory Units (LMUs) are a novel memory cell for recurrent neural networks, described in Voelker, Kajić, and Eliasmith (NeurIPS 2019). We will not go into the underlying details of these methods here; for our purposes we can think of this as an alternative to something like LSTMs. LMUs have achieved state of the art performance on complex RNN tasks, which we will demonstrate here. See the paper for all the details!
In this example we will show how an LMU can be built in NengoDL, and used to solve the Permuted Sequential MNIST (psMNIST) task.
First we need to set up the data for this task. We begin with the standard MNIST dataset of handwritten digits:
[1]:
%matplotlib inline
from urllib.request import urlretrieve
import matplotlib.pyplot as plt
import nengo
from nengo.utils.filter_design import cont2discrete
import numpy as np
import tensorflow as tf
import nengo_dl
# set seed to ensure this example is reproducible
seed = 0
tf.random.set_seed(seed)
np.random.seed(seed)
rng = np.random.RandomState(seed)
# load mnist dataset
(train_images, train_labels), (
test_images,
test_labels,
) = tf.keras.datasets.mnist.load_data()
# change inputs to 0--1 range
train_images = train_images / 255
test_images = test_images / 255
# reshape the labels to rank 3 (as expected in Nengo)
train_labels = train_labels[:, None, None]
test_labels = test_labels[:, None, None]
plt.figure()
plt.imshow(np.reshape(train_images[0], (28, 28)), cmap="gray")
plt.axis("off")
plt.title(str(train_labels[0, 0, 0]))
plt.show()
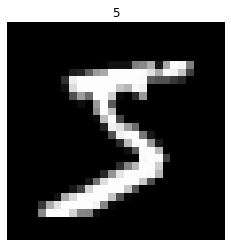
“Sequential” MNIST refers to taking the pixels of the images and flattening them into a sequence of single pixels. Each pixel will be presented to the network one at a time, and the goal of the network is to classify the sequence according to which digit it represents.
[2]:
# flatten images into sequences
train_images = train_images.reshape((train_images.shape[0], -1, 1))
test_images = test_images.reshape((test_images.shape[0], -1, 1))
# we'll display the sequence in 8 rows just so that it fits better on the screen
plt.figure()
plt.imshow(train_images[0].reshape(8, -1), cmap="gray")
plt.axis("off")
plt.title(str(train_labels[0, 0, 0]))
plt.show()

As we can see, after flattening the image there is still a decent amount of structure remaining. “Permuted” sequential MNIST makes the task more difficult by applying a fixed permutation to all of the image sequences. This ensures that the information contained in the image is distributed evenly throughout the sequence, so the RNN really does need to process the whole length of the input sequence.
[3]:
# apply permutation
perm = rng.permutation(train_images.shape[1])
train_images = train_images[:, perm]
test_images = test_images[:, perm]
plt.figure()
plt.imshow(train_images[0].reshape(8, -1), cmap="gray")
plt.axis("off")
plt.title(str(train_labels[0, 0, 0]))
plt.show()
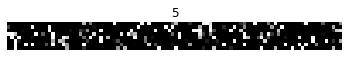
Next we define the LMU cell. This is a modified version of the implementation from KerasLMU; see the documentation there for more details. A single LMU cell is implementing this computational graph:

[4]:
class LMUCell(nengo.Network):
def __init__(self, units, order, theta, input_d, **kwargs):
super().__init__(**kwargs)
# compute the A and B matrices according to the LMU's mathematical derivation
# (see the paper for details)
Q = np.arange(order, dtype=np.float64)
R = (2 * Q + 1)[:, None] / theta
j, i = np.meshgrid(Q, Q)
A = np.where(i < j, -1, (-1.0) ** (i - j + 1)) * R
B = (-1.0) ** Q[:, None] * R
C = np.ones((1, order))
D = np.zeros((1,))
A, B, _, _, _ = cont2discrete((A, B, C, D), dt=1.0, method="zoh")
with self:
nengo_dl.configure_settings(trainable=None)
# create objects corresponding to the x/u/m/h variables in the above diagram
self.x = nengo.Node(size_in=input_d)
self.u = nengo.Node(size_in=1)
self.m = nengo.Node(size_in=order)
self.h = nengo_dl.TensorNode(tf.nn.tanh, shape_in=(units,), pass_time=False)
# compute u_t from the above diagram. we have removed e_h and e_m as they
# are not needed in this task.
nengo.Connection(
self.x, self.u, transform=np.ones((1, input_d)), synapse=None
)
# compute m_t
# in this implementation we'll make A and B non-trainable, but they
# could also be optimized in the same way as the other parameters.
# note that setting synapse=0 (versus synapse=None) adds a one-timestep
# delay, so we can think of any connections with synapse=0 as representing
# value_{t-1}.
conn_A = nengo.Connection(self.m, self.m, transform=A, synapse=0)
self.config[conn_A].trainable = False
conn_B = nengo.Connection(self.u, self.m, transform=B, synapse=None)
self.config[conn_B].trainable = False
# compute h_t
nengo.Connection(
self.x, self.h, transform=nengo_dl.dists.Glorot(), synapse=None
)
nengo.Connection(
self.h, self.h, transform=nengo_dl.dists.Glorot(), synapse=0
)
nengo.Connection(
self.m,
self.h,
transform=nengo_dl.dists.Glorot(),
synapse=None,
)
And then we construct a simple network consisting of an input node, a single LMU cell, and a dense linear readout. It is also possible to chain multiple LMU cells together, but that is not necessary in this task.
[5]:
with nengo.Network(seed=seed) as net:
# remove some unnecessary features to speed up the training
nengo_dl.configure_settings(
trainable=None,
stateful=False,
keep_history=False,
)
# input node
inp = nengo.Node(np.zeros(train_images.shape[-1]))
# lmu cell
lmu = LMUCell(
units=212,
order=256,
theta=train_images.shape[1],
input_d=train_images.shape[-1],
)
conn = nengo.Connection(inp, lmu.x, synapse=None)
net.config[conn].trainable = False
# dense linear readout
out = nengo.Node(size_in=10)
nengo.Connection(lmu.h, out, transform=nengo_dl.dists.Glorot(), synapse=None)
# record output. note that we set keep_history=False above, so this will
# only record the output on the last timestep (which is all we need
# on this task)
p = nengo.Probe(out)
And now we can train the model. To save time in this example we will download some pretrained weights, but you can set do_training=True below to run the training yourself. Note that even with do_training=True we’re only training for 10 epochs, which is dramatically less than many other solutions to this task. We could train for longer if we wanted to really fine-tune performance.
[6]:
do_training = False
with nengo_dl.Simulator(net, minibatch_size=100, unroll_simulation=16) as sim:
sim.compile(
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam(),
metrics=["accuracy"],
)
test_acc = sim.evaluate(test_images, test_labels, verbose=0)["probe_accuracy"]
print(f"Initial test accuracy: {test_acc * 100:.2f}%")
if do_training:
sim.fit(train_images, train_labels, epochs=10)
sim.save_params("./lmu_params")
else:
urlretrieve(
"https://drive.google.com/uc?export=download&"
"id=1UbVJ4u6eQkyxIU9F7yScElAz2p2Ah2sP",
"lmu_params.npz",
)
sim.load_params("./lmu_params")
test_acc = sim.evaluate(test_images, test_labels, verbose=0)["probe_accuracy"]
print(f"Final test accuracy: {test_acc * 100:.2f}")
Build finished in 0:00:00
Optimization finished in 0:00:00
Construction finished in 0:00:01
Initial test accuracy: 7.98%
Final test accuracy: 96.15
We can see that the network is achieving >96% accuracy, which is state of the art performance on psMNIST.