
- Introduction
- Installation
- User guide
- API reference
- Examples
- Coming from Nengo to NengoDL
- Coming from TensorFlow to NengoDL
- Integrating a Keras model into a Nengo network
- Optimizing a spiking neural network
- Converting a Keras model to a spiking neural network
- Legendre Memory Units in NengoDL
- Optimizing a cognitive model
- Optimizing a cognitive model with temporal dynamics
- Additional resources
- Project information
Coming from Nengo to NengoDL¶
![]()
NengoDL combines two frameworks: Nengo and TensorFlow. This tutorial is designed for people who are familiar with Nengo and looking to take advantage of the new features of NengoDL. For the other approach, users familiar with TensorFlow looking to learn how to use NengoDL, check out this tutorial.
Simulating a network with NengoDL¶
We’ll begin by defining a simple Nengo network to use as an example. The goal of our network will be to compute \(sin(x^2)\). There is nothing particularly significant about this network or function; the same principles we will discuss here could be applied to any Nengo model.
[1]:
%matplotlib inline
import warnings
import matplotlib.pyplot as plt
import nengo
import numpy as np
import tensorflow as tf
import nengo_dl
# ignore some efficiency warnings since this tutorial isn't designed to be
# highly optimized
warnings.simplefilter("ignore")
tf.get_logger().addFilter(lambda rec: "Tracing is expensive" not in rec.msg)
tf.get_logger().addFilter(lambda rec: "slow compared to the batch time" not in rec.msg)
# we'll control the random seed in this example to make sure things stay
# consistent, but the results don't depend significantly on the seed
# (try changing it to verify)
seed = 0
np.random.seed(seed)
[2]:
with nengo.Network(seed=seed) as net:
# input node outputting a random signal for x
inpt = nengo.Node(nengo.processes.WhiteSignal(1, 5, rms=0.3))
# first ensemble, will compute x^2
square = nengo.Ensemble(20, 1)
# second ensemble, will compute sin(x^2)
sin = nengo.Ensemble(20, 1)
# output node
outpt = nengo.Node(size_in=1)
# connect everything together
nengo.Connection(inpt, square)
nengo.Connection(square, sin, function=np.square)
nengo.Connection(sin, outpt, function=np.sin)
# add a probe on the input and output
inpt_p = nengo.Probe(inpt)
outpt_p = nengo.Probe(outpt, synapse=0.01)
We can simulate this network in the regular Nengo simulator:
[3]:
with nengo.Simulator(net, seed=seed) as sim:
sim.run(1.0)
And plot the output:
[4]:
def plot(plot_sim, ax=None, idx=slice(None)):
if ax is None:
plt.figure()
ax = plt.gca()
ax.plot(plot_sim.trange(), plot_sim.data[inpt_p][idx], label="x")
ax.plot(
plot_sim.trange(), np.sin(plot_sim.data[inpt_p][idx] ** 2), label="sin(x^2)"
)
ax.plot(plot_sim.trange(), plot_sim.data[outpt_p][idx], label="output")
ax.legend()
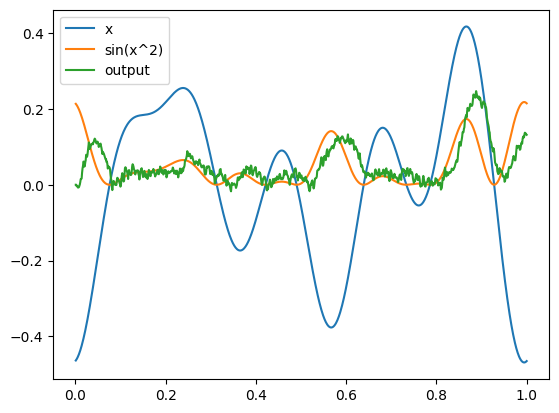
plot(sim)
To run the same network in NengoDL, all we need to do is switch nengo.Simulator to nengo_dl.Simulator:
[5]:
with nengo_dl.Simulator(net, seed=seed) as sim:
sim.run(1.0)
plot(sim)
Build finished in 0:00:00
Optimization finished in 0:00:00
Construction finished in 0:00:06
Simulation finished in 0:00:15
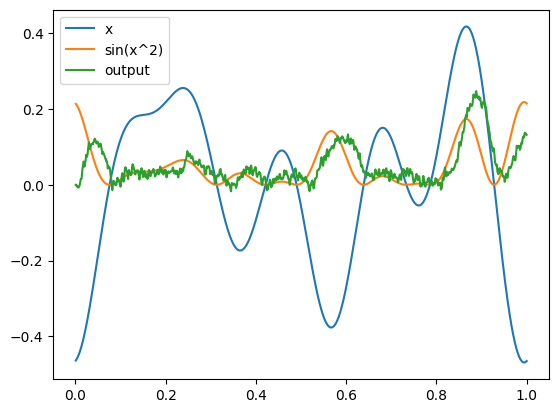
Note that the output of the NengoDL simulator is the same as the standard Nengo simulator. Switching to NengoDL will not impact the behaviour of a model at all (ignoring very minor floating point math differences); any model that can run in Nengo will also run in NengoDL and produce the same output.
However, NengoDL adds a number of new features on top of the standard Nengo simulator, which we will explore next.
Batch processing¶
Often when testing a model we want to run it several times with different input values. In regular Nengo we can achieve this by calling sim.run several times, resetting between each run:
[6]:
reps = 3
with nengo.Simulator(net) as sim:
_, axes = plt.subplots(1, reps, figsize=(20, 4.8))
for i in range(reps):
sim.run(1.0)
plot(sim, ax=axes[i])
sim.reset(seed=i + 10)
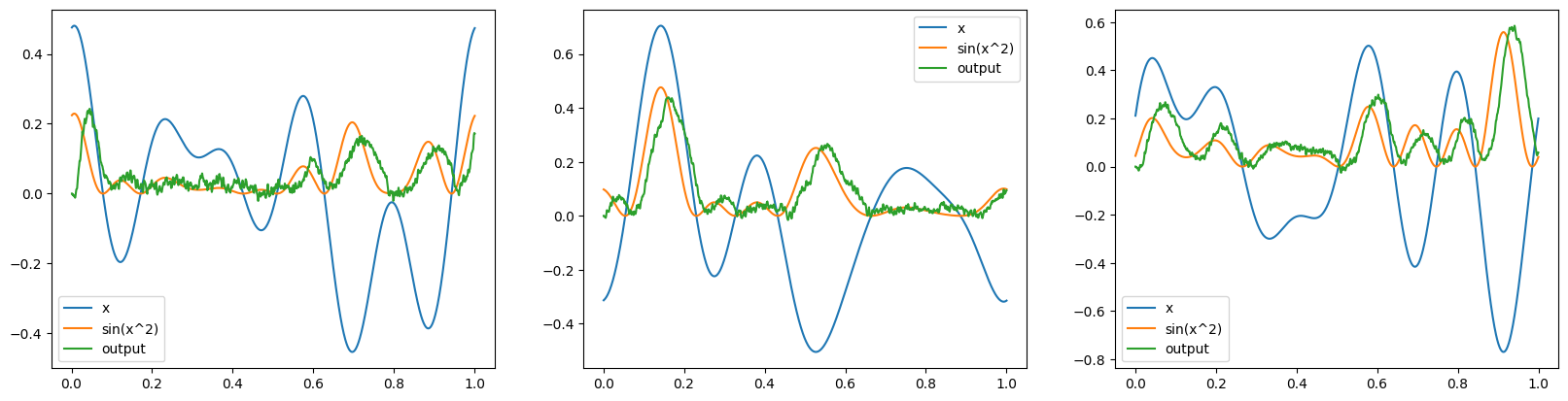
Note that simulating n different input sequences in this way takes n times as long as a single input sequence.
NengoDL, on the other hand, allows us to run several input values through the network in parallel. This is known as “batch processing”. This can significantly improve the simulation time, as we can parallelize the computations and achieve much better than linear scaling.
This is controlled through the minibatch_size parameter of the NengoDL simulator. To accomplish the same thing as above, but with a single parallelized call to sim.run, we can do:
[7]:
with nengo_dl.Simulator(net, minibatch_size=reps) as sim:
sim.run(1.0)
_, axes = plt.subplots(1, reps, figsize=(20, 4.8))
for i in range(reps):
plot(sim, ax=axes[i], idx=i)
Build finished in 0:00:00
Optimization finished in 0:00:00
Construction finished in 0:00:00
Simulation finished in 0:00:00
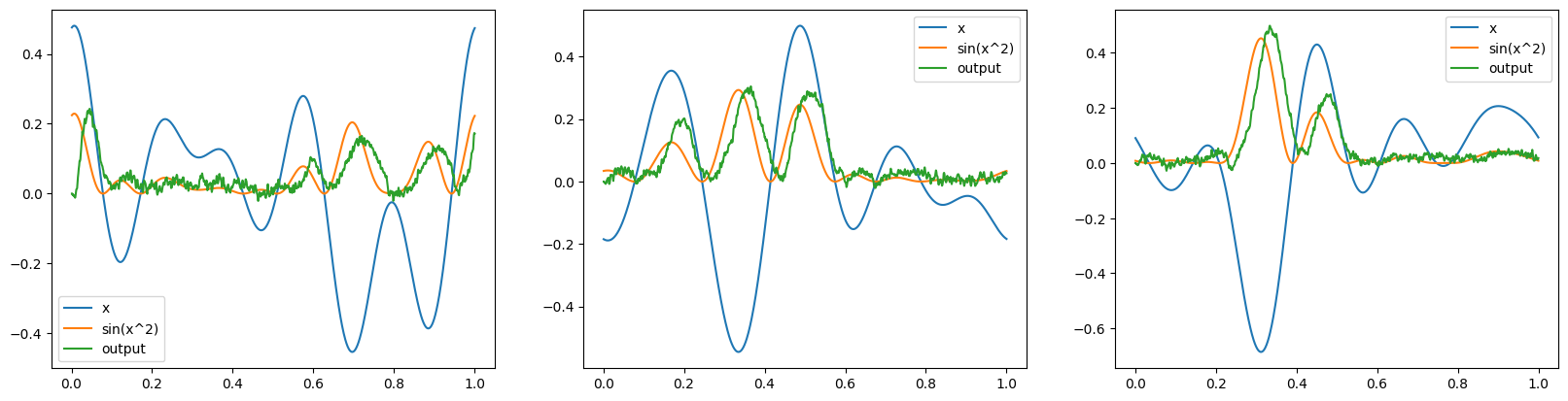
Note that in this case the inputs and outputs aren’t matching between the two simulators because we’re not worrying about controlling the random seed. But we can see that the network has run three different simulations in a single parallel run.
Specifying model inputs at run time¶
In standard Nengo, input values are specified in the model definition (when we create a nengo.Node). At run time, the model is then simulated with those input values every time; if we want to change the input values, we need to change the Node. However, it can be useful to dynamically specify the input values at run time, so that we can simulate the model with different input values without changing our model definition.
NengoDL supports this through the data argument. This is a dictionary that maps Nodes to arrays, where each array has shape (minibatch_size, n_steps, node_size). minibatch_size refers to the Simulator.minibatch_size parameter discussed in the previous section, n_steps is the number of simulation time steps, and node_size is the output dimensionality of the Node.
For example, we could simulate our network with a linear ramp input:
[8]:
with nengo_dl.Simulator(net) as sim:
sim.run(1.0, data={inpt: np.reshape(np.linspace(-1, 1, 1000), (1, 1000, 1))})
plot(sim)
Build finished in 0:00:00
Optimization finished in 0:00:00
Construction finished in 0:00:00
Simulation finished in 0:00:00
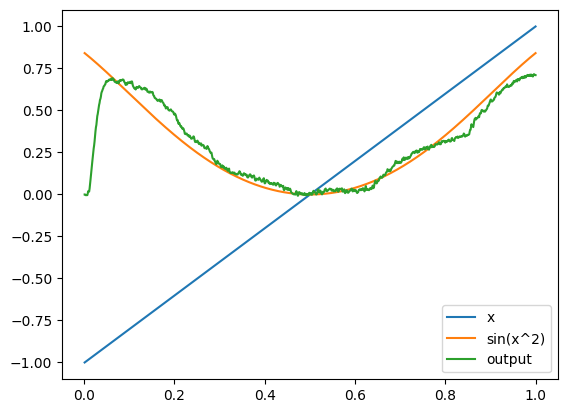
Note that we didn’t change the model definition at all. In theory, our Node is still outputting the same random signal, but we overrode that with the values in data.
This functionality is particularly useful in concert with batch processing, as it allows us to provide different input values for each item in the batch. For example, we could run each batch item with a different ramp input:
[9]:
with nengo_dl.Simulator(net, minibatch_size=reps) as sim:
sim.run(
1.0,
data={
inpt: (
np.linspace(0.5, 1, reps)[:, None, None]
* np.linspace(-1, 1, 1000)[None, :, None]
)
},
)
_, axes = plt.subplots(1, reps, figsize=(20, 4.8))
for i in range(reps):
plot(sim, ax=axes[i], idx=i)
axes[i].set_ylim((-1, 1))
Build finished in 0:00:00
Optimization finished in 0:00:00
Construction finished in 0:00:00
Simulation finished in 0:00:00
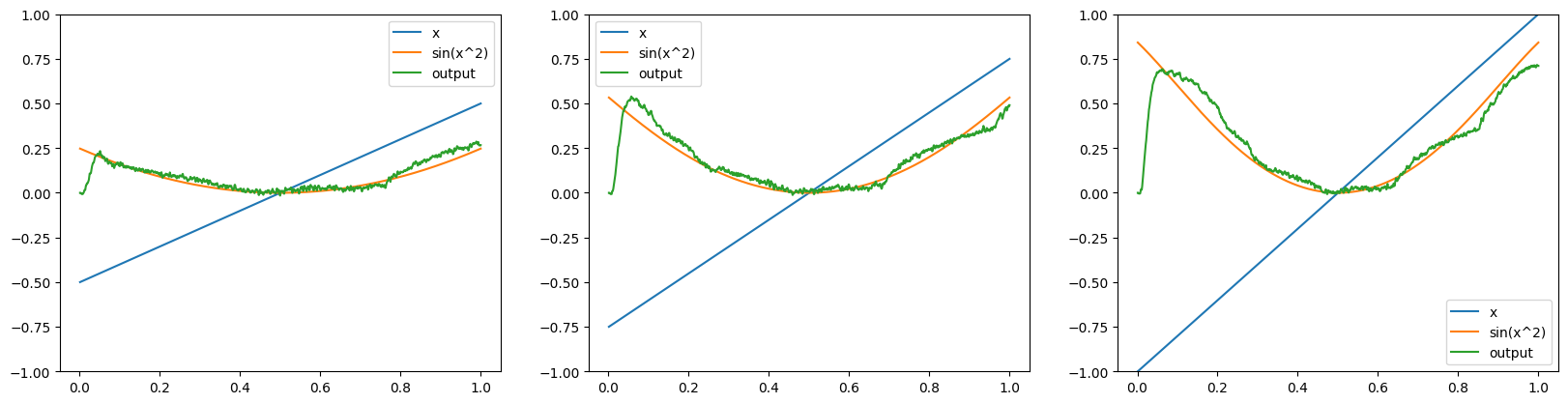
Optimizing model parameters¶
By default, Nengo uses the Neural Engineering Framework to optimize the parameters of a model. NengoDL adds a new set of optimization tools (deep learning training methods) to that toolkit, which can be used instead of or in addition to the NEF optimization.
Which techniques work best will depend on the particular model being developed. However, as a general rule of thumb the deep learning methods will tend to take longer but provide more accurate network output. One reason for this is that deep learning methods can jointly optimize across all the parameters in the network (e.g., adjusting the decoders for multiple chained connections so that they work together to compute a function), whereas the NEF optimization is applied to each connection individually. Deep learning methods can also optimize all the parameters in a network (encoders, decoders, and biases), whereas NEF methods are only applied to decoders. We’ll illustrate this difference in this example by using a hybrid approach, where we use the NEF to compute the decoders and deep learning methods to optimize encoders and biases.
First we’re going to make some changes to the model itself. We created the model with the default synaptic filter of nengo.Lowpass(tau=0.005) on all the Connections. This makes sense when we’re working with a spiking model, as the filters reduce the spike noise in the communication between Ensembles. However, when we’re training a network in NengoDL the synaptic filters introduce more complex temporal dynamics into the optimization problem. This is not necessarily a bad thing, as those
temporal dynamics may be something we care about and want to optimize for. But in this instance we don’t particularly care about the synaptic dynamics. During training NengoDL will automatically be swapping the spiking nengo.LIF neuron model for the non-spiking nengo.LIFRate, so we don’t need the synaptic filters to reduce spike noise. And because this is a simple feedforward network, there aren’t any other temporal dynamics in the system that the synaptic filtering would interact with.
So we can simplify our optimization problem by removing the synaptic filters, without significantly changing the behaviour of our model.
[10]:
# set all the connection synapses to None
for conn in net.all_connections:
conn.synapse = None
# add a new probe that doesn't have a synaptic filter on it
# (we'll keep the original probe with the synaptic filter
# as well, since we'll have uses for both)
with net:
outpt_p_nofilt = nengo.Probe(outpt)
# increase the filtering on our output probe (to compensate
# for the fact that we removed the internal synaptic filters)
outpt_p.synapse = 0.04
We can verify that our network still produces roughly the same output after these changes.
[11]:
with nengo_dl.Simulator(net, seed=seed) as sim:
sim.run(1.0)
plot(sim)
Build finished in 0:00:00
Optimization finished in 0:00:00
Construction finished in 0:00:00
Simulation finished in 0:00:01
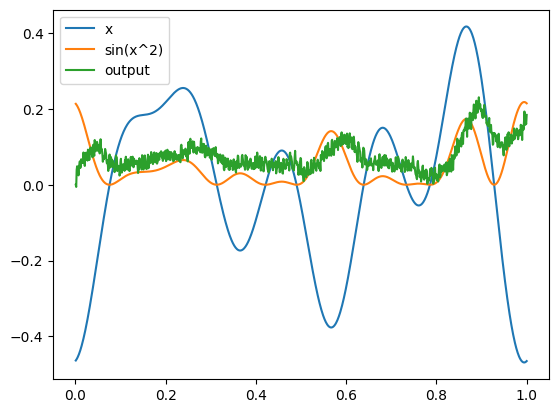
Next we will select how we want to optimize this network. As discussed above, in this example we’re going to leave the decoders the same, and apply our deep learning optimization to the encoders and biases. We can control which parts of a model will be optimized through the trainable configuration attribute. More details on how this works can be found in the documentation.
[12]:
with net:
# disable optimization on all parameters by default
nengo_dl.configure_settings(trainable=False)
# re-enable training on Ensembles (encoders and biases)
net.config[nengo.Ensemble].trainable = True
Next we need to define our training data. This consists of two parts: input values for Nodes, and target values for Probes. These indicate that when the network receives the given input values, we want to see the corresponding target values at the probe. The data is specified as a dictionary mapping nodes/probes to arrays. This is much the same as the data argument introduced above, and the arrays have a similar shape (batch_size, n_steps, node/probe_size). Note that batch_size in
this case can be greater than minibatch_size, and the data will automatically be divided up into minibatch_size chunks during training.
In this example n_steps will just be 1, meaning that we will only be optimizing the model parameters with respect to a single timestep of inputs and outputs. Because we have eliminated the temporal dynamics in our model by removing the synaptic filters, each timestep can be treated independently. That is, training with a batch size of 1 for 1000 timesteps is the same as training with a batch size of 1000 for 1 timestep. And the latter is preferred, as the computations will be more efficient
when we can divide them into minibatches and parallelize them.
Note that if our model had temporal dynamics (e.g., through recurrent connections or synaptic filters) then it would be important to train with n_steps>1, in order to capture those dynamics. But we don’t need to worry about that in this case, nor in many common deep-learning-style networks, so we’ll keep things simple. See this example for a more complex problem where temporal dynamics are involved.
[13]:
batch_size = 4096
minibatch_size = 32
n_steps = 1
# create random input data
vals = np.random.uniform(-1, 1, size=(batch_size, n_steps, 1))
# create data dictionaries
inputs = {inpt: vals}
targets = {outpt_p_nofilt: np.sin(vals**2)}
Now we are ready to optimize our model. This is done through the sim.compile and sim.fit functions. In addition to the inputs/targets, there are three more arguments we need to think about.
The first is which deep learning optimization algorithm we want to use when training the network. Essentially these algorithms define how to turn an error value into a change in the model parameters (with the goal being to reduce the error). There are many options available, which we will not go into here. We’ll use RMSProp, which is a decent default in many cases.
Second, we need to think about the objective function. This is the function that computes an error value given the network outputs (for example, by computing the difference between the output and target values). Again there are many options here that we will not go into; choosing an appropriate objective function depends on the nature of a particular task. In this example we will use mean squared error, which is generally a good default.
The third parameter we’ll set is epochs. This determines how many training iterations we will execute; one epoch is one complete pass through the training data. This is a parameter that generally needs to be set through trial and error; it will depend on the particular optimization task.
See the documentation for a more in-depth discussion of sim.fit parameters and usage.
[14]:
with nengo_dl.Simulator(net, minibatch_size=minibatch_size, seed=seed) as sim:
sim.compile(
optimizer=tf.optimizers.Adam(0.01), loss={outpt_p_nofilt: tf.losses.mse}
)
sim.fit(inputs, targets, epochs=25)
sim.run(1.0)
plot(sim, idx=0)
Build finished in 0:00:00
Optimization finished in 0:00:00
Construction finished in 0:00:00
Epoch 1/25
128/128 [==============================] - 3s 6ms/step - loss: 0.0015 - probe_2_loss: 0.0015
Epoch 2/25
128/128 [==============================] - 1s 6ms/step - loss: 0.0011 - probe_2_loss: 0.0011
Epoch 3/25
128/128 [==============================] - 1s 6ms/step - loss: 8.6869e-04 - probe_2_loss: 8.6869e-04
Epoch 4/25
128/128 [==============================] - 1s 6ms/step - loss: 7.1414e-04 - probe_2_loss: 7.1414e-04
Epoch 5/25
128/128 [==============================] - 1s 6ms/step - loss: 6.1816e-04 - probe_2_loss: 6.1816e-04
Epoch 6/25
128/128 [==============================] - 1s 6ms/step - loss: 5.5498e-04 - probe_2_loss: 5.5498e-04
Epoch 7/25
128/128 [==============================] - 1s 6ms/step - loss: 5.1330e-04 - probe_2_loss: 5.1330e-04
Epoch 8/25
128/128 [==============================] - 1s 6ms/step - loss: 4.8409e-04 - probe_2_loss: 4.8409e-04
Epoch 9/25
128/128 [==============================] - 1s 6ms/step - loss: 4.5908e-04 - probe_2_loss: 4.5908e-04
Epoch 10/25
128/128 [==============================] - 1s 6ms/step - loss: 4.3521e-04 - probe_2_loss: 4.3521e-04
Epoch 11/25
128/128 [==============================] - 1s 6ms/step - loss: 4.1512e-04 - probe_2_loss: 4.1512e-04
Epoch 12/25
128/128 [==============================] - 1s 6ms/step - loss: 3.9752e-04 - probe_2_loss: 3.9752e-04
Epoch 13/25
128/128 [==============================] - 1s 6ms/step - loss: 3.8629e-04 - probe_2_loss: 3.8629e-04
Epoch 14/25
128/128 [==============================] - 1s 6ms/step - loss: 3.7111e-04 - probe_2_loss: 3.7111e-04
Epoch 15/25
128/128 [==============================] - 1s 6ms/step - loss: 3.5935e-04 - probe_2_loss: 3.5935e-04
Epoch 16/25
128/128 [==============================] - 1s 6ms/step - loss: 3.5116e-04 - probe_2_loss: 3.5116e-04
Epoch 17/25
128/128 [==============================] - 1s 6ms/step - loss: 3.4109e-04 - probe_2_loss: 3.4109e-04
Epoch 18/25
128/128 [==============================] - 1s 6ms/step - loss: 3.3030e-04 - probe_2_loss: 3.3030e-04
Epoch 19/25
128/128 [==============================] - 1s 6ms/step - loss: 3.2307e-04 - probe_2_loss: 3.2307e-04
Epoch 20/25
128/128 [==============================] - 1s 6ms/step - loss: 3.2079e-04 - probe_2_loss: 3.2079e-04
Epoch 21/25
128/128 [==============================] - 1s 6ms/step - loss: 3.1435e-04 - probe_2_loss: 3.1435e-04
Epoch 22/25
128/128 [==============================] - 1s 6ms/step - loss: 3.0722e-04 - probe_2_loss: 3.0722e-04
Epoch 23/25
128/128 [==============================] - 1s 6ms/step - loss: 3.0025e-04 - probe_2_loss: 3.0025e-04
Epoch 24/25
128/128 [==============================] - 1s 6ms/step - loss: 2.9450e-04 - probe_2_loss: 2.9450e-04
Epoch 25/25
128/128 [==============================] - 1s 6ms/step - loss: 2.8924e-04 - probe_2_loss: 2.8924e-04
Simulation finished in 0:00:01
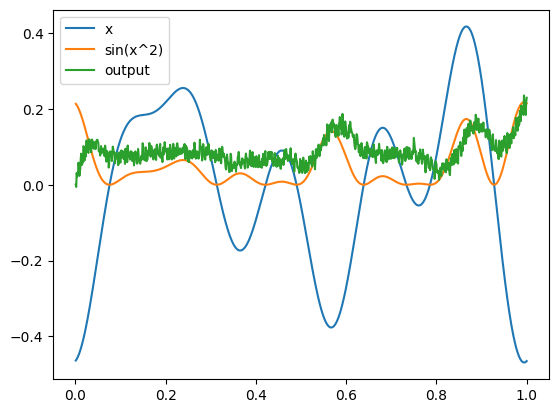
If we compare this to the figure above, we can see that there has been some improvement. However, it is better to use a quantitative measure of performance, discussed next.
Evaluating model performance¶
As discussed above, the goal with training is usually to reduce some error value. In order to evaluate how successful our training has been it is helpful to check what the value of that error is before and after optimization. This can be done through the sim.evaluate function.
sim.evaluate works very analogously to sim.fit; we pass it some data, and it will compute an error value (based on the loss functions we specified in sim.compile). Note that we can also evaluate loss functions other than those used during training, by using the metrics argument of sim.compile.
It is almost always the case that we want to use a different data set for evaluating the model’s performance than we used during training. Otherwise we might think that training has improved the performance of our model in general, when in fact it has only improved performance on that specific training data. This is known as overfitting.
[15]:
# create new set of random test data
test_vals = np.random.uniform(-1, 1, size=(1024, 1, 1))
Another important factor to keep in mind is that during training the spiking neurons in the model are automatically being swapped for differentiable rate neurons. This is one of the reasons that we only needed to run the training for a single timestep (rate neurons compute their output instantaneously, whereas spiking neurons need to accumulate voltage and spike over time). By default, sim.evaluate does not change the neuron models in this way. This is what we want, because it is the
performance of the model we defined, which contains spiking neurons, that we want to evaluate. However, this does mean that we need to increase the value of n_steps for the testing data. In addition, we will use the output probe with the synaptic filter, in order to get a less noisy estimate of the model’s output.
[16]:
# repeat test data for a number of timesteps
test_steps = 100
test_vals = np.tile(test_vals, (1, test_steps, 1))
# create test data dictionary
# note: using outpt_p instead of outpt_p_nofilt
test_inputs = {inpt: test_vals}
test_targets = {outpt_p: np.sin(test_vals**2)}
We’ll also define a custom objective function. The initial output of the model will be dominated by startup artifacts (e.g., synaptic filter effects), and not indicative of the model’s optimized performance. So we’ll define a version of mean squared error that only looks at the model’s output from the last 10 timesteps, in order to get a more meaningful measure of how much the performance improves with training.
[17]:
def test_mse(y_true, y_pred):
return tf.reduce_mean(tf.square(y_pred[:, -10:] - y_true[:, -10:]))
Now we are ready to evaluate the model’s performance. We will do the same thing we did in the training example above, but also evaluate the performance of our model on the test data before and after training.
[18]:
with nengo_dl.Simulator(net, minibatch_size=minibatch_size, seed=seed) as sim:
sim.compile(loss={outpt_p: test_mse})
print("Error before training:", sim.evaluate(test_inputs, test_targets)["loss"])
# run the training, same as in the previous section
print("Training")
sim.compile(
optimizer=tf.optimizers.Adam(0.01), loss={outpt_p_nofilt: tf.losses.mse}
)
sim.fit(inputs, targets, epochs=25)
sim.compile(loss={outpt_p: test_mse})
print("Error after training:", sim.evaluate(test_inputs, test_targets)["loss"])
Build finished in 0:00:00
Optimization finished in 0:00:00
Construction finished in 0:00:00
32/32 [==============================] - 3s 65ms/step - loss: 0.0040 - probe_1_loss: 0.0040
Error before training: 0.003992334473878145
Training
Epoch 1/25
128/128 [==============================] - 3s 6ms/step - loss: 0.0015 - probe_2_loss: 0.0015
Epoch 2/25
128/128 [==============================] - 1s 6ms/step - loss: 0.0011 - probe_2_loss: 0.0011
Epoch 3/25
128/128 [==============================] - 1s 6ms/step - loss: 8.6869e-04 - probe_2_loss: 8.6869e-04
Epoch 4/25
128/128 [==============================] - 1s 6ms/step - loss: 7.1414e-04 - probe_2_loss: 7.1414e-04
Epoch 5/25
128/128 [==============================] - 1s 6ms/step - loss: 6.1816e-04 - probe_2_loss: 6.1816e-04
Epoch 6/25
128/128 [==============================] - 1s 6ms/step - loss: 5.5498e-04 - probe_2_loss: 5.5498e-04
Epoch 7/25
128/128 [==============================] - 1s 6ms/step - loss: 5.1330e-04 - probe_2_loss: 5.1330e-04
Epoch 8/25
128/128 [==============================] - 1s 6ms/step - loss: 4.8409e-04 - probe_2_loss: 4.8409e-04
Epoch 9/25
128/128 [==============================] - 1s 6ms/step - loss: 4.5908e-04 - probe_2_loss: 4.5908e-04
Epoch 10/25
128/128 [==============================] - 1s 6ms/step - loss: 4.3521e-04 - probe_2_loss: 4.3521e-04
Epoch 11/25
128/128 [==============================] - 1s 6ms/step - loss: 4.1512e-04 - probe_2_loss: 4.1512e-04
Epoch 12/25
128/128 [==============================] - 1s 6ms/step - loss: 3.9752e-04 - probe_2_loss: 3.9752e-04
Epoch 13/25
128/128 [==============================] - 1s 6ms/step - loss: 3.8629e-04 - probe_2_loss: 3.8629e-04
Epoch 14/25
128/128 [==============================] - 1s 6ms/step - loss: 3.7111e-04 - probe_2_loss: 3.7111e-04
Epoch 15/25
128/128 [==============================] - 1s 6ms/step - loss: 3.5935e-04 - probe_2_loss: 3.5935e-04
Epoch 16/25
128/128 [==============================] - 1s 6ms/step - loss: 3.5116e-04 - probe_2_loss: 3.5116e-04
Epoch 17/25
128/128 [==============================] - 1s 6ms/step - loss: 3.4109e-04 - probe_2_loss: 3.4109e-04
Epoch 18/25
128/128 [==============================] - 1s 6ms/step - loss: 3.3030e-04 - probe_2_loss: 3.3030e-04
Epoch 19/25
128/128 [==============================] - 1s 6ms/step - loss: 3.2307e-04 - probe_2_loss: 3.2307e-04
Epoch 20/25
128/128 [==============================] - 1s 6ms/step - loss: 3.2079e-04 - probe_2_loss: 3.2079e-04
Epoch 21/25
128/128 [==============================] - 1s 6ms/step - loss: 3.1435e-04 - probe_2_loss: 3.1435e-04
Epoch 22/25
128/128 [==============================] - 1s 6ms/step - loss: 3.0722e-04 - probe_2_loss: 3.0722e-04
Epoch 23/25
128/128 [==============================] - 1s 6ms/step - loss: 3.0025e-04 - probe_2_loss: 3.0025e-04
Epoch 24/25
128/128 [==============================] - 1s 6ms/step - loss: 2.9450e-04 - probe_2_loss: 2.9450e-04
Epoch 25/25
128/128 [==============================] - 1s 6ms/step - loss: 2.8924e-04 - probe_2_loss: 2.8924e-04
32/32 [==============================] - 3s 70ms/step - loss: 0.0031 - probe_1_loss: 0.0031
Error after training: 0.0030983116012066603
We can now say with more confidence that optimizing the encoders and biases has improved the accuracy of the model.
Integrating TensorFlow code¶
Another important feature of NengoDL is the ability to add TensorFlow code into a Nengo model. For example, we could use a convolutional vision network, defined in TensorFlow, as the input to a cognitive Nengo model. However, we’ll keep things simple in this example and just use TensorFlow to compute the exponent of our output (so that overall the network is computing \(e^{\sin(x^2)}\)). Note that for something like this we don’t really need to use TensorFlow; we can accomplish the same thing with normal Nengo syntax. The goal here is just to introduce the methodology in a simple case; see this example for a more practical example of integrating TensorFlow code in NengoDL.
TensorFlow code is inserted using TensorNodes. A TensorNode works much the same way as a regular nengo.Node, except that instead of specifying the Node output using Python/NumPy functions, we use TensorFlow functions.
[19]:
with net:
# here is how we would accomplish this with a regular nengo Node
exp_np = nengo.Node(lambda t, x: np.exp(x), size_in=1)
nengo.Connection(outpt, exp_np)
np_probe = nengo.Probe(exp_np, synapse=0.01)
# here is how we do the same using a TensorNode
exp_tf = nengo_dl.TensorNode(lambda t, x: tf.exp(x), shape_in=(1,))
nengo.Connection(outpt, exp_tf)
tf_probe = nengo.Probe(exp_tf, synapse=0.01)
with nengo_dl.Simulator(net, seed=seed) as sim:
sim.run(1.0)
plt.figure()
plt.plot(sim.trange(), np.exp(np.sin(sim.data[inpt_p] ** 2)), label="e^sin(x^2)")
plt.plot(sim.trange(), sim.data[np_probe], label="Node output")
plt.plot(sim.trange(), sim.data[tf_probe], label="TensorNode output", linestyle="--")
plt.ylim([0.8, 1.4])
plt.legend()
plt.show()
Build finished in 0:00:00
Optimization finished in 0:00:00
Construction finished in 0:00:00
Simulation finished in 0:00:01
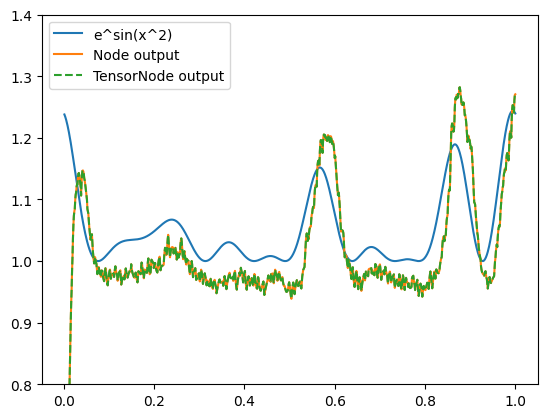
We can see that the nengo.Node and nengo_dl.TensorNode are producing the same output, as we would expect. But under the hood, one is being computed in NumPy and the other is being computed in TensorFlow.
More details on TensorNode usage can be found in the user guide.
Conclusion¶
In this tutorial we have introduced the NengoDL Simulator, batch processing, dynamically specifying input values, optimizing model parameters using deep learning methods, and integrating TensorFlow code into a Nengo model. This will allow you to begin to take advantage of the new features NengoDL adds to the Nengo toolkit. However, there is much more functionality in NengoDL than we are able to introduce here; check out the user guide or other examples for more information.