- NengoLoihi
- How to Build a Brain
- Tutorials
- A Single Neuron Model
- Representing a scalar
- Representing a Vector
- Addition
- Arbitrary Linear Transformation
- Nonlinear Transformations
- Structured Representations
- Question Answering
- Question Answering with Control
- Question Answering with Memory
- Learning a communication channel
- Sequencing
- Routed Sequencing
- Routed Sequencing with Cleanup Memory
- Routed Sequencing with Cleanup all Memory
- 2D Decision Integrator
- Requirements
- License
- Tutorials
- NengoCore
- Ablating neurons
- Deep learning
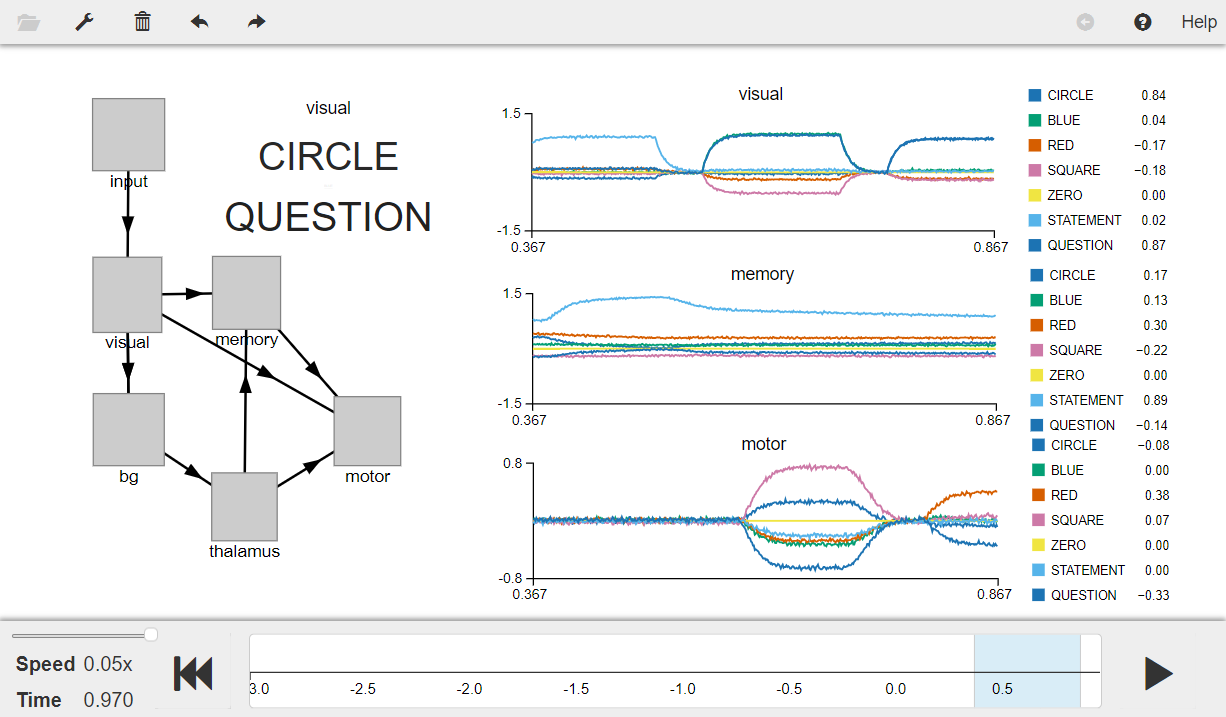
Question Answering with Control¶
This model shows a form of question answering where statements and questions are supplied through a single “visual input” and the replies are produced in a “motor output” as discussed in the book. You will implement this by using the Basal Ganglia to store and retrieve information from working memory in response to visual input. More specifically, the Basal Ganglia decides what to do with the information in the visual channel based on its content (i.e. whether it is a statement or a question).
Note: Simplified method of building the model using the SPA (semantic pointer architecture) package in Nengo 2.0 is shown in the last few sections of this notebook.
[1]:
# Setup the environment
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
import nengo
from nengo.spa import Vocabulary
from nengo.dists import Uniform
Create the model¶
This model has parameters as described in the book. Note that in Nengo 1.4, network arrays were used to construct this model for computational reasons as explained in the book. Nengo 2.0 has ‘EnsembleArray’ as an equivalent to network arrays which you will use in this model.
When you run the model, it will start by binding RED and CIRCLE and then binding BLUE and SQUARE so the memory essentially has RED * CIRCLE + BLUE * SQUARE. This is stored in memory because the model is told that RED * CIRCLE is a STATEMENT (i.e. RED * CIRCLE + STATEMENT in the code) as is BLUE * SQUARE. Then it is presented with something like QUESTION + RED (i.e., “What is red?”). The Basal Ganglia then reroutes that input to be compared to what is in working memory and the result shows up in the motor channel.
[2]:
dim = 100 # Number of dimensions
n_neurons = 30 # Neurons per dimension
n_conv = 70 # Number of neurons per dimension in bind/unbind populations
n_mem = 50 # Number of neurons per dimension in memory population
# Defining a zero vector having length equal to the number of dimensions
ZERO = [0] * dim
# Creating the vocabulary
rng = np.random.RandomState(15)
vocab = Vocabulary(dimensions=dim, rng=rng, max_similarity=0.05)
# Create the network object to which we can add ensembles, connections, etc.
model = nengo.Network(label="Question Answering with Control", seed=15)
with model:
# Ensembles
visual = nengo.networks.EnsembleArray(
n_neurons=n_neurons,
n_ensembles=dim,
max_rates=Uniform(100, 300),
label="Visual",
)
channel = nengo.networks.EnsembleArray(
n_neurons=n_neurons, n_ensembles=dim, label="Channel"
)
motor = nengo.networks.EnsembleArray(
n_neurons=n_neurons, n_ensembles=dim, label="Motor"
)
# Creating a memory (integrator)
tau = 0.1
memory = nengo.networks.EnsembleArray(
n_neurons=n_mem, n_ensembles=dim, label="Memory"
)
nengo.Connection(memory.output, memory.input, synapse=tau)
# Function for providing visual input
def visual_input(t):
if 0.1 < t < 0.3:
return vocab.parse("STATEMENT+RED*CIRCLE").v
elif 0.35 < t < 0.5:
return vocab.parse("STATEMENT+BLUE*SQUARE").v
elif 0.55 < t < 0.7:
return vocab.parse("QUESTION+BLUE").v
elif 0.75 < t < 0.9:
return vocab.parse("QUESTION+CIRCLE").v
return ZERO
# Function for flipping the output of the thalamus
def x_biased(x):
return [1 - x]
# Providing input to the model
vis_stim = nengo.Node(output=visual_input, size_out=dim, label="Input stimulus")
nengo.Connection(vis_stim, visual.input)
nengo.Connection(visual.output, channel.input, synapse=0.02)
nengo.Connection(channel.output, memory.input)
# Creating the unbind network
unbind = nengo.networks.CircularConvolution(
n_neurons=n_conv, dimensions=dim, invert_a=True
)
nengo.Connection(visual.output, unbind.A)
nengo.Connection(memory.output, unbind.B)
nengo.Connection(unbind.output, motor.input)
# Creating the basal ganglia and the thalamus network
bg = nengo.networks.BasalGanglia(dimensions=2)
thal = nengo.networks.Thalamus(dimensions=2)
nengo.Connection(bg.output, thal.input, synapse=0.01)
# Defining the transforms for connecting the visual input to the BG
trans0 = np.matrix(vocab.parse("STATEMENT").v)
trans1 = np.matrix(vocab.parse("QUESTION").v)
nengo.Connection(visual.output, bg.input[0], transform=trans0)
nengo.Connection(visual.output, bg.input[1], transform=trans1)
# Connecting thalamus output to the gates on the channel and the motor populations
passthrough = nengo.Ensemble(n_neurons, 2)
nengo.Connection(thal.output, passthrough)
gate0 = nengo.Ensemble(n_neurons, 1, label="Gate0")
nengo.Connection(passthrough[0], gate0, function=x_biased, synapse=0.01)
gate1 = nengo.Ensemble(n_neurons, 1, label="Gate1")
nengo.Connection(passthrough[1], gate1, function=x_biased, synapse=0.01)
for ensemble in channel.ea_ensembles:
nengo.Connection(gate0, ensemble.neurons, transform=[[-3]] * gate0.n_neurons)
for ensemble in motor.ea_ensembles:
nengo.Connection(gate1, ensemble.neurons, transform=[[-3]] * gate1.n_neurons)
Add Probes to Collect Data¶
[3]:
with model:
Visual_p = nengo.Probe(visual.output, synapse=0.03)
Motor_p = nengo.Probe(motor.output, synapse=0.03)
Memory_p = nengo.Probe(memory.output, synapse=0.03)
Run The Model¶
[4]:
with nengo.Simulator(model) as sim: # Create the simulator
sim.run(1.2) # Run it for 1.2 seconds
Plot The Results¶
[5]:
plt.figure(figsize=(10, 10))
plt.subplot(6, 1, 1)
plt.plot(sim.trange(), nengo.spa.similarity(sim.data[Visual_p], vocab))
plt.legend(vocab.keys, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.0, fontsize=9)
plt.ylabel("Visual")
plt.subplot(6, 1, 2)
plt.plot(sim.trange(), nengo.spa.similarity(sim.data[Memory_p], vocab))
plt.legend(vocab.keys, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.0, fontsize=9)
plt.ylabel("Memory")
plt.subplot(6, 1, 3)
plt.plot(sim.trange(), nengo.spa.similarity(sim.data[Motor_p], vocab))
plt.legend(vocab.keys, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.0, fontsize=9)
plt.ylabel("Motor")
[5]:
Text(0, 0.5, 'Motor')
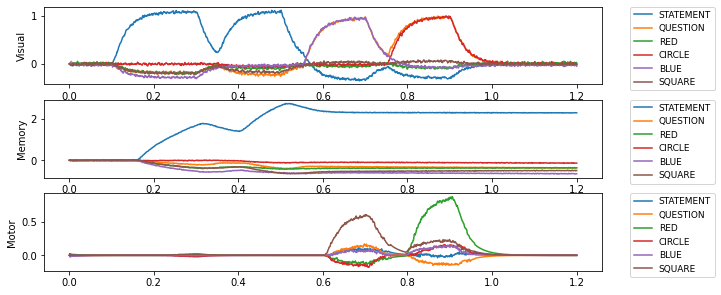
The graphs above show that when the input to the visual system is a STATEMENT, there is no response from the motor system and the input is stored in the memory. However, when the input to the visual system is a QUESTION, the motor system responds with the appropriate answer. For instance, when the input to visual system is QUESTION + CIRCLE the output from the motor system is RED (as the memory previously stored RED * CIRCLE).
Create the model using the nengo.spa package¶
[6]:
from nengo import spa
dim = 32 # The dimensionality of the vectors
rng = np.random.RandomState(11)
vocab = Vocabulary(dimensions=dim, rng=rng, max_similarity=0.1)
# Adding semantic pointers to the vocabulary
CIRCLE = vocab.parse("CIRCLE")
BLUE = vocab.parse("BLUE")
RED = vocab.parse("RED")
SQUARE = vocab.parse("SQUARE")
ZERO = vocab.add("ZERO", [0] * dim)
# Create the spa.SPA network to which we can add SPA objects
model = spa.SPA(label="Question Answering with Control", vocabs=[vocab])
with model:
model.visual = spa.State(dim)
model.motor = spa.State(dim)
model.memory = spa.State(dim, feedback=1, feedback_synapse=0.1)
actions = spa.Actions(
"dot(visual, STATEMENT) --> memory=visual",
"dot(visual, QUESTION) --> motor = memory * ~visual",
)
model.bg = spa.BasalGanglia(actions)
model.thalamus = spa.Thalamus(model.bg)
# Function for providing visual input
def visual_input_spa(t):
if 0.1 < t < 0.3:
return "STATEMENT+RED*CIRCLE"
elif 0.35 < t < 0.5:
return "STATEMENT+BLUE*SQUARE"
elif 0.55 < t < 0.7:
return "QUESTION+BLUE"
elif 0.75 < t < 0.9:
return "QUESTION+CIRCLE"
return "ZERO"
# Inputs
model.input = spa.Input(visual=visual_input_spa)
Run the model in nengo_gui¶
[ ]:
from nengo_gui.ipython import IPythonViz
IPythonViz(model, "ch5-question-control.py.cfg")
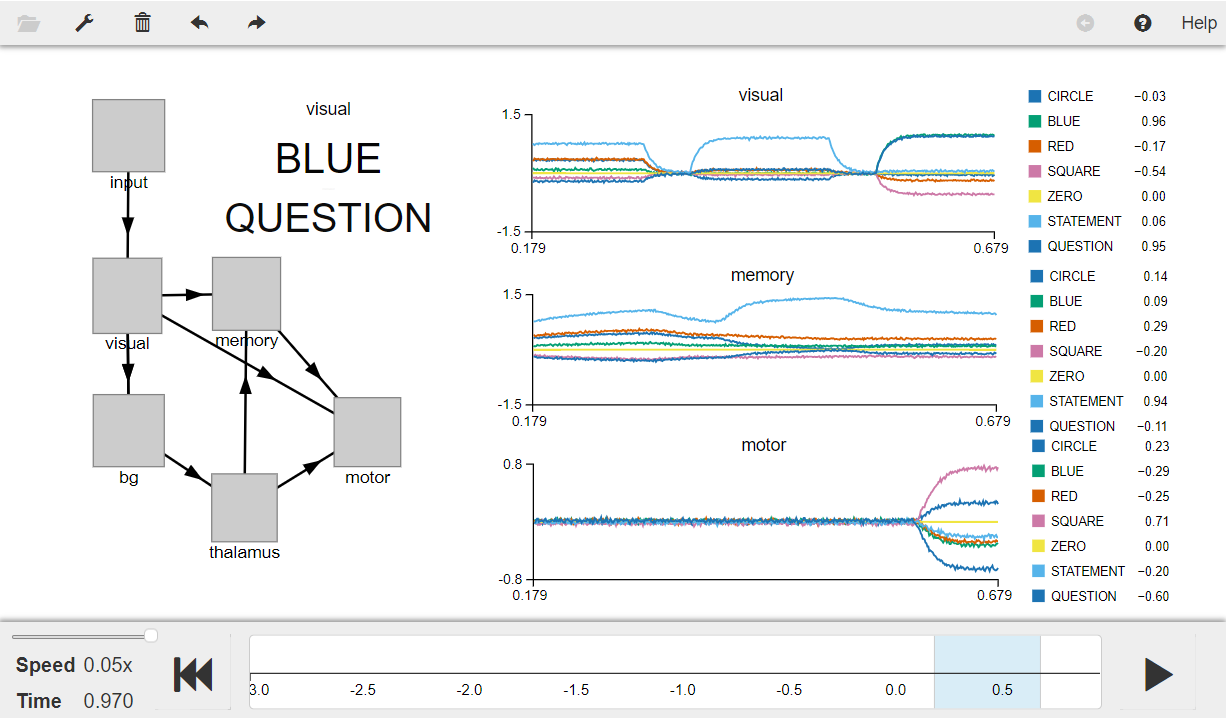
Press the play button in the visualizer to run the simulation. You should see the “semantic pointer cloud” graphs as shown in the figure below.
The visual graph shows the input represented by visual. When this input is a STATEMENT, there is no response shown in the motor graph and the input is stored in memory (shown in memory graph). However, when the input to the visual is a QUESTION, the motor graph shows the appropriate answer. For instance, when the input to visual is QUESTION + BLUE (shown in the visual graphs), the output from motor is SQUARE.
[7]:
from IPython.display import Image
Image(filename="ch5-question-control-1.png")
[7]:
[8]:
Image(filename="ch5-question-control-2.png")
[8]: